HTTP (Hypertext Transfer Protocol) is the foundation of the web that allows browsers and servers to communicate.
It is was created by Tim Berners-Lee and its purpose is to help retrieve HTML docs, images, videos, and other multimedia files using hypertext links.
Before this, users had to download and open files with a suitable program on their computers in order to view them.
How does HTTP work?
HTTP usually works like this: a client asks the server for a webpage, and the server sends back that webpage.
We call the former request and the latter response.
In computer science, networks use this request–response process as the basic method of communication between a client and a server and we call it request-response cycle.

Let’s describe it in more detail.
1. Client Request: A user types a URL (e.g., http://example.com) in her broswer.
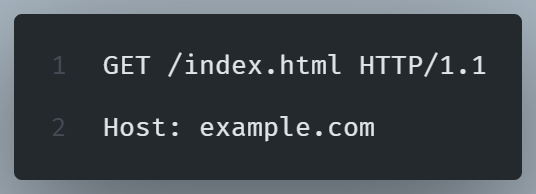
2. HTTP Request: The browser creates an HTTP request. This request allows the server to send a response to the client, based on the information provided via a request header such as the HTTP version, method, and HTTP headers.
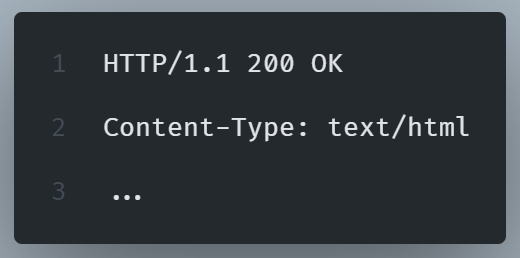
3. Server Response: The server precesses the request and sends back an HTTP response containing headers, status codes, and the requested content.
4. Content Display: The browser receives the response and renders (produces) the webpage from the received resources.
Conclusion
HTTP is not the only protocol specifically created for the internet.
There are several other Internet Protocols that serve different purposes.
HTTP focuses on web content transfer between browsers and servers.
What makes it ideal for this job is that it can support various types of data transfer beyond just hypertext documents and its stateless nature.