A search query is a phrase or keyword a user enters in a search engine in order to find what she is looking for.
To prepare for these search queries, search engines perform many behind-the-scenes operations to compile a list of websites, keywords, and phrases.
This list is called an index.
But in order to compile that list, SEs need to first discover the websites, keywords, and phrases that answer a specific search query.
This process of discovering the right web pages is called crawling.
Search engine crawlers (also called spiders or bots) are automated programs that browse the web to discover and index content.
Most search engines rely on proprietary web crawlers.
Google’s search engine crawler, Googlebot and Microsoft’s search engine crawler, Bingbot are some examples of well-known web crawlers.
How Do Crawlers Work?
Crawlers start with a list of known web pages and find new ones by following internal links (links within the same website) or/and external links (links from one website to another).
Apart from links, sitemaps, XML files that list a website’s pages, can also help crawling for larger, more complex, websites.
Crawling the Page
Once a crawler finds a URL, it fetches the page and analyzes its content (text, images, videos, etc.), its meta tags (title, description) and links.
To make sure search engine crawlers can find crawl a site efficiently, we can follow these crawlability optimization tips:
1. Optimize Site Structure
- There should be a clear hierarchy with categories, subcategories, and internal links.
- Crucial pages should be no more than a few clicks away from the homepage.
- Utilize breadcrumb navigation to help users (and crawlers) understand site structure.
2. Optimize Internal Linking
- Important pages should be linked from other pages within the website.
- Links should use descriptive anchor text (not just “click here”).
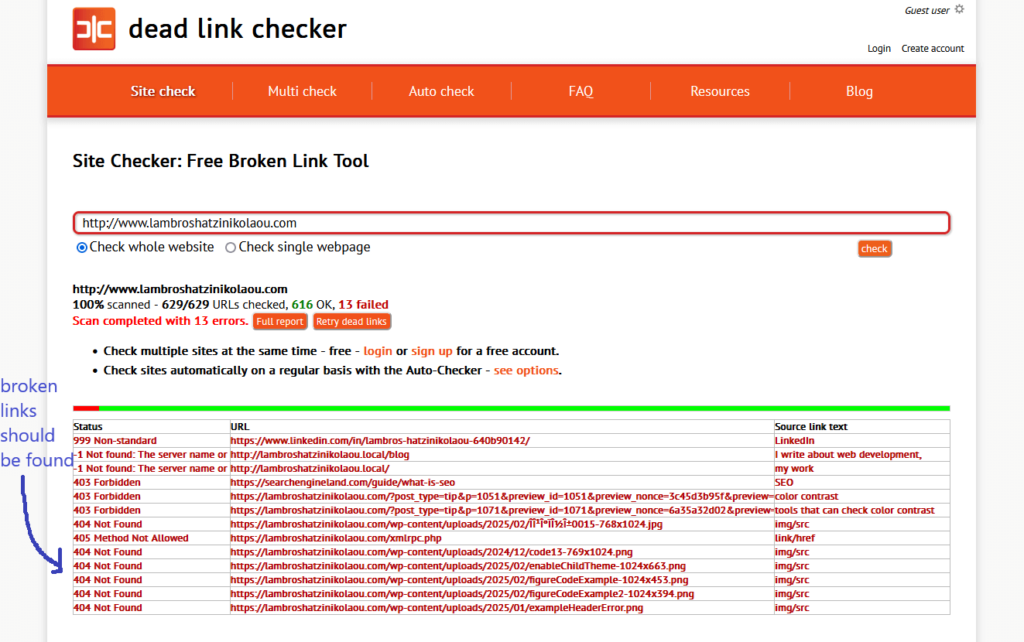
- Broken links must be found and fixed (tools like Google Search Console can help to find and fix them).
3. Submit a Sitemap
- Submit sitemap to Google Search Console & Bing Webmaster Tools.
- Keep it updated as new content is added.
NOTE: Your sitemap should be at yourwebsite.com/sitemap.xml.
4. Fix Crawl Errors
- Google Search Console can help finding crawl issues. Google Search Console → Coverage Reports.
- Broken links (404 errors) should be fixed & outdated pages should be redirected(301 redirects).
- Pages should load fast & being free from JavaScript or CSS errors.
5. Avoid Duplicate Content
Canonical tags (rel=”canonical”) point search engines to the original/preferred version of a page.

Now all duplicate URLs should point to the prefered page.
RUles for canonnical tags
- Canonical tags should be placed in the <head> section of the HTML.
- Only one canonical is permitted per page.
- The page’s URL should be absolute (not relative paths).
- Meta descriptions & titles should be unique.
How frequently are websites visited by web crawlers?
Search engines don’t just crawl once—they revisit pages regularly to check for updates. Pages with frequent changes (like news sites) get crawled more often.
Is it possible to prevent web crawlers from accessing a website?
We can use a robots.txt file to manage which site sections web crawlers can and cannot crawl.
By implementing the ‘Disallow’ directive, we can block pages we don’t want crawled (like login pages).
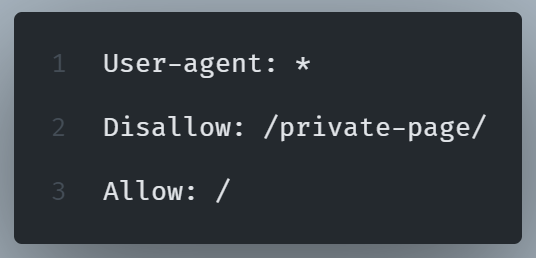
NOTE: Test robots.txt file in Google Search Console (yourwebsite.com/robots.txt).
Monitor Crawling
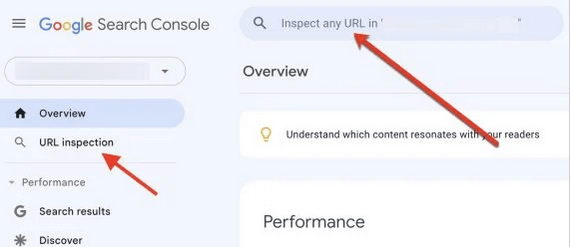
We can monitor Crawling with Google Search Console
There are several things we can do with Google Search Console.
For example;
- Check the Crawl Stats report for bot activity.
- Use the URL Inspection Tool to see if a page is indexed.
- Submit important new pages for faster indexing.
Why is Crawling Important for SEO?
If search engines can’t crawl a page, it won’t appear in search results.
Once spiders have crawled a page, SE will decide if the content gets indexed. Indexing depends on several factors, like rendering, that we are going to see in more detail later.